

Hoy en día el software es un elemento muy importante en nuestra sociedad, y podemos decir que se encuentra presente en muchos de los productos y servicios que utilizamos cada día.
Multitud de dispositivos que nos rodean nos facilitan el trabajo en cualquier ámbito de nuestra vida (ocio, transportes..), y lo más probable es que lleve instalado algún tipo de software de control.
Es por ello, que los profesionales del desarrollo de software necesitan conocer y dominar un determinado tipo de herramientas las cuales permite controlar y gestionar de una manera organizada y realmente potente el desarrollo, evolución y mantenimiento de cualquier producto o servicio en cuyo corazón se ejecuten instrucciones de control.
Saber que se dispone de versiones de software anteriores, permite tener la tranquilidad de trabajar en nuevas características con la seguridad de que pueden ser restauradas en cualquier momento si algo recientemente desarrollado no funciona correctamente.
Una de estas herramientas es Git. Se trata de una herramienta diseñada por Linus Torvalds que permite llevar a cabo el control de versiones de código fuente, llevando un control de los cambios realizados con rigurosidad y coordinando las contribuciones de un equipo de desarrolladores en un mismo proyecto.
Una característica importante que marca la diferencia de Git con respecto a otras herramientas del mismo propósito es que se trata de un sistema de control de versiones distribuido, lo que significa que cada componente del equipo tiene un copia local de la historia completa de proyecto, pudiendo trabajar "offline" y posteriormente sincronizar los cambios al repositorio base que contiene la versión final, la cual se ubica en datacenters o en la nube.
 |
| Equipo de desarrolladores contribuyendo a un repositorio remoto de trabajo común. |
La ubicación de los repositorios remotos donde se almacena la versión final del proyecto es posible determinarla en plataformas web donde se lleva a cabo el hosting de dichos proyectos y donde se implementa el control de versiones mediante Git. Ejemplos de ello son Github o Bitbucket.


Github es un portal de tipo social y colaborativo para soportar el desarrollo de software libre y comercial. En esta plataforma se gestionan grandes proyectos de software libre.
Además, Github no sirve solamente para gestionar el desarrollo de software en equipo, si que permite el distribuir a terceros dicho software, ya que los proyectos públicos son accesibles por cualquiera y muestran toda la estructura del proyecto (versiones, cambios generados, ramas, contribuidores).
A continuación se resumen algunos de los conceptos básicos de uso y manejo de Git y Github, los cuales pueden servir como introducción a este set de herramientas que cualquier desarrollador de software debe dominar.
A la hora de trabajar con Git, es posible hacerlo mediante línea de comandos (p.e. Git Bash para Windows) o mediante un cliente gráfico (p.e. Sourcetree). Estas son algunas de las ventajas al utilizar la opción de línea de comandos:
- Las habilidades de línea de comandos son asumidas por la industria, con lo que conviene conocerlas.
- En línea de comandos es posible realizar automatizaciones, algo muy relacionado con los test.
- Cuando se domina, es rápido y fácil de usar.
- Los clientes gráficos como Sourcetree son muy útiles en ciertos momentos cuando se realizan tareas donde prima la componente visual.
Relación de terminología básica a conocer para trabajar en Git:
- Commit: Un commit (confirmación) recoge el estado de un proyecto en un determinado momento de la historia del mismo.
- Directorio de trabajo: Se trata del directorio donde se encuentran almacenador los ficheros que componen el proyecto. El directorio contiene metadatos gestionados por Git, de manera que el proyecto es configurado como un repositorio local.
- Referencias y objetos: En git es posible hablar de dos tipos de elementos, los objetos (commits) y las referencias que apuntan a dichos objetos. Existen varios tipos de referencias como son head, tag, remotos o etiquetas de rama. Cada objeto se encuentra representado por un código SHA-1 único. Dicho código es lo que subyace detrás de cada una de las referencias.
- Rama (branch): es una sucesión de commits que representan la evolución o hitoria de un proyecto o una parte del mismo. Las ramas pueden utilizarse con diferentes propósitos como desarrollo, construcción de partes concretas de un proyecto, liberalización de versiones..
Referencia HEAD
Head es una referencia que apunta al commit actual en el que estamos ubicados dentro del árbol del proyecto. Normalmente apunta a la cabeza de una determinada rama, existiendo solamente una referencia Head por cada repositorio.
 |
| Referencia HEAD apuntando al último commit de la rama master |

Rama Tracking
Una tracking branch, es una rama local que representa una rama en un repositorio remoto. Se representa mediante el nombre del remoto + "/" + el nombre de la rama (p.e. origin/master).
Las ramas remotas tracking solamente se sincronizan con sus ramas a las que representan del repositorio remoto, cuando se ejecutan comandos de red como git clone, git fetch, git pull y git push.
| Representación en el repositorio local de la rama remota master (origin/master) |
A la hora de configurar un repositorio local enlazado a un repositorio remoto de manera que sea posible el comenzar a trabajar en el proyecto utilizando esta estructura, es posible encontrarse dos escenarios:
- Solamente existe repositorio remoto: Si se dispone de un repositorio remoto pero no de repositorio local (Creado en Github/Bitbucket), el primer paso a realizar es clonar dicho repositorio en el PC de trabajo (git clone), de manera que ya es posible trabajar y sincronizar los resultado en el repositorio remoto.
- Solamente existe repositorio local: En esta situación será necesario crear el repositorio remoto para almacenar el resultado final del proyecto. Una vez creado, será necesario configurar el enlace del repositorio local y remoto para que pueda realizarse la sincronización adecuadamente. Esto se realiza creando una referencia al repositorio remoto (git remote add).
A grandes rasgos es posible diferenciar los comandos en git, entre aquellos destinados a ser utilizados para manejar el directorio de trabajo local o aquellos cuyo objetivo es gestionar el repositorio remoto enlazado al repositorio local.
Un resumen de comando de manejo del repositorio local son los siguientes:
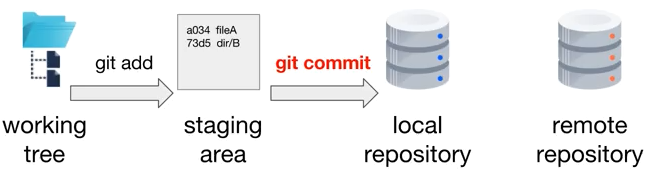
git init
Configura un directorio para que sea monitorizado por Git. Para ello, configura el directorio de trabajo, compuesto por los ficheros del proyecto, el índice o staging area y un repositorio local donde se almacenarán los commits.
En relación a esto, en git existen varias localizaciones a diferenciar en un proyecto:
- Directorio de trabajo (o árbol de trabajo): Es el conjunto de ficheros que forman el proyecto en un determinado momento de la historia del mismo, los cuales se han extraído del repositorio y están listos para utilizarse a conveniencia.
- Índice (staging area): Representa la zona donde se ubican los ficheros modificados del proyecto, que serán incluidos en el siguiente commit (fotografía del proyecto).
- Repositorio (.git): Se trata del lugar en el que git almacena en modo de base de datos, toda la información (metadata) del proyecto así como su evolución, albergando todas las ramas y los commits que forman la historia del proyecto.

git add
Añade ficheros untracked y modificados al índice (staging area). Conviene saber que en git, un fichero que forma parte del proyecto puede estar en los siguientes estados:
- untracked: No se encuentra monitorizado.
- unmodified: Se encuentra monitorizado pero no ha sido modificado.
- modified: Es un fichero monitorizado y modificado.
- staged: El fichero se encuentra listo para ser incluido en el próximo commit.

git reset
Inverso a git add, extrae del índice los ficheros indicados devolviéndolos al directorio de trabajo.
git commit
Realiza una nueva "fotografía" del proyecto en su estado actual. De esta manera, se crea un nuevo commit en la historia del proyecto.
git commit -m "descripción"
git status
Indica la situación actual de los ficheros que componen el directorio de trabajo (modificados, untracked o staged).
git status -s

git log
Muestra la historia de commits del proyecto de manera visual, donde es posible ver la evolución del proyecto desarrollado.
git log --oneline --oneline --graph --all
git log <rama o rama tracking> --oneline --graph --all
git diff
Muestra las diferencias introducidas entre dos objetos (ficheros, árbol de trabajo, commits)
git diff Fichero.txt
NOTA: Usando de modo combinado los comandos git log y git diff, es posible averiguar qué cambios se realizaron en un contexto de determinado. Mediante git log es posible mostrar todos los commits almacenados en el repositorio, de manera que es posible averiguar mediante las descripciones asociadas a cada commit el tipo de cambios llevados a cabo en un determinado momento.
A continuación, se puede pasar a estudiar en detalle un determinado commit, para ver exactamente los cambios que se llevaron a cabo.
git mv
Permite mover o renombrar un fichero, incluso en el índice.
git mv File1.txt File2.txt
git rm
Borrar ficheros del directorio de trabajo y del índice.
git rm File1.txt File2.txt
git rm --cached File1.txt File2.txt (Borra del índice ficheros pasando de staged a untracked)
git branch
Permite manejar y gestionar las ramas existentes en el repositorio.
git branch --all Muestra las distintas ramas existentes en el proyecto, locales y remotas. La rama actual local, la que se encuentra seleccionada (checked out) se muestra con un asterisco *.
La rama remota por defecto, se indica mediante la referencia HEAD. En el caso siguiente, se trataría de origin/master, con lo que nos podemos referir a ella en los comandos como simplemente origin:
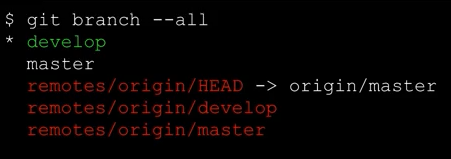
De esta manera, si necesitásemos por ejemplo subir cambios a la rama remota develop del ejemplo anterior de manera constante, podríamos definir que el remoto por defecto fuese origin/develop, y así ahorrar trabajo a la hora de escribir los comandos. Se utilizaría el comando:
git remote set-head origin develop

git branch <nombrerama> permite crear una branch label en el commit actual, es decir, permite crear una nueva rama.
git branch -d <nombrerama> permite eliminar una etiqueta de rama o branch label (no elimina commits). Normalmente es utilizado este comando tras haber realizado un merge de la rama a eliminar en la rama principal. Si lo aplicamos a una rama antes de hacer un mege, git nos lo impedirá, indicando que utilicemos -D para realizarlo verdaderamente. Una vez hecho, los commits asociados a la rama eliminada quedarán huérfanos, entendiéndose que deseamos desechar el trabajo realizado. Si finalmente fue un error, es posible deshacer la borrado de la rama mediante git reflog, donde podremos consultar el id o sha-1 del último commit de la rama eliminada y así ejectuar
git checkout -b <nombrerama> <sha-1 commit> para restablecer la situación inicial.
git checkout
Permite conmutar entre las diferentes ramas de las que se compone un proyecto.
git checkout <nombrerama> permite cambiar de la rama actual, a la rama indicada. Es decir, la referencia HEAD cambia a la branch label indicada.
git checkout -b <nombrerama> realiza en un solo comando la creación y selección de la rama indicada. Es decir, se crea una nueva rama y el HEAD apuntará a ésta nueva rama.
git checkout File1.txt File2.txt Hace un Revert y deja los ficheros indicados como en la versión anterior.
git checkout * revierte los cambios de todos los ficheros actualmente modificados.
NOTA: Al realizar un checkout de un fichero que se encuentra subido al índice (staged), el resultado será que se sobreescribe el mismo fichero en el directorio de trabajo con la versión del fichero staged. Si por el contrario se realiza un checkout de un fichero que no se encuentra en el índice, éste se sobrescribirá con la última versión (último commit).
git remote
Permite gestionar los repositorios remotos cuyas ramas se están monitorizando (tracking branches).
git remote add <nombre> <URL> Para el caso de tener un repositorio local y haber creado un repositorio remoto a posteriori con el mismo nombre, se establece la referencia entre ellos de esta manera, creando un remote con un determinado nombre (origin es lo habitual).
git remote -v Muestra los repositorios remotos asociados al repositorio local
git tag
Permite gestinar las diferentes etiquetas ubicadas en los distintos commits
git tag permite visualizar las tags de tipo "annotated " existentes en el repositorio.
git tag -a [-m <mensaje> | -F <fichero>] <nombretag> [<commit>] permite crear una annotated tag en el commit indicado. Si no se especifica commit se utilizará el que apunte HEAD.
git tag -d <nombretag> permite eliminar la tag indicada.

git show
Muestra la información asociada a uno o varios objetos.
git show <nombretag> Permite visualizar la información que recoge una tag concreta.
git show tambien puede utilizarse para extraer la información asociada a un commit indicando algunas de sus referencias, como HEAD, el SHA-1 (identificador), o incluso la rama (git show HEAD, git show 337c50f, o git show master).
git show HEAD~ muestra la información del primer ancestro de HEAD (git show HEAD~2 sería del segundo, y así sucesivamente..)
git show HEAD^ muestra, al igual que el comando anterior, la información del ancentro, pero git show HEAD^2 muestra la información del segundo ancestro de HEAD en la rama merge en caso de existir.
git merge
Realiza la integración de una rama en otra, generándose la unión de las dos historias de commits.
git merge <nombrerama> Hace un merge de <nombrerama> sobre la rama actual.
git merge --no-ff <nombrerama> Hace un merge sobre la rama actual, pero indicando que genere un merge commit incluso en el caso de poder realizarse un fast-forward (en algunos equipos de trabajo se imponen esta regla, quedando constancia del merge en un commit independiente).
NOTA: Para evitar conflictos al hacer merge, se recomienda hacer pequeños y frecuentes merges.
Es mejor tener varios conflictos pequeños al hacer merge, que uno solamente pero de enormes proporciones.

NOTA: El proceso automático merging de Git puede ahorrar mucho tiempo al desarrollador, especialmente cuando hay un equipo de trabajo detrás. Sin embargo, el proceso no es perfecto. Por ejemplo, si una rama ha borrado una determinada función, y otra rama diferente añade una llamada a esta función, Git finalizará el proceso de merge sin detectar conflictos, pero el resultado es que el código no funcionará. La conclusión es que es muy importante comprobar que el código sigue funcionado después de realizar un merge.
Merge con commit asociado (merge commit):

Merge tipo fast-forward (sin merge commit):

Set de comandos básicos de trabajo sobre el repositorio remoto
git clone
Crea un repositorio local clon del repositorio remoto.
git clone url

git fetch
Comando que permite descargar nuevos objetos (commits) y referencias (branches..) desde el repositorio remoto.
Principalmente realiza la actualización de todas las ramas tracking.
Permite descarga y visualizar los cambios del repositorio remoto sin realizar un merge con nuestro trabajo en local.
git fech url

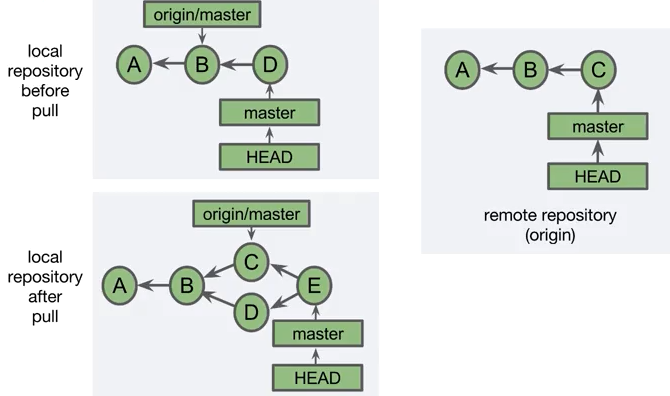
git pull
git pull combina un git fetch y un git merge de la rama tracking con la rama local. Se descargan los nuevos objetos y referencias del repositorio remoto, y se hace un merge en la rama local. Similar a un merge de una topic branch en la base branch.
Opciones:
--ff (por defecto) hace un merge fast-forward siempre que sea posible
--no-ff siempre genera un commit al hacer un merge (crea un merge commit)
--ff-only solo realiza el merge si es posible hacerlo fast-forward.
A continuación se muestra el resultado de un git pull tipo fast-forward:
 |
 |
git push
git push añade nuevos objetos y referencias al repositorio remoto con información del repositorio local.
NOTA: Se sugiere hacer un fetch o un pull antes de hacer un push.
Si se lleva a cabo un push y no tenemos en local la última versión del repositorio remoto, entonces el push fallará. Si en cambio, ejecutamos un fetch y vemos que no se han descargado objetos, entonces sabremos que podemos llevar a cabo un push con seguridad.
Si nos preocupa hacer un pull y que genere un merge commit, podemos utilizar la opción --ff-only
git push [-u] <repositorio> <rama> realiza una copia de la rama local indicada, sobre el repositorio remoto (origin). [-u] indica que se realice un tracking de la rama (únicamente la primera vez que se realiza un push), para que git informe cuando está out-of-synch.
git push <remote> <nombretag> Transfiere al repositorio remoto la tag creada, ya que las tags no se suben al repositorio remoto de forma predeterminada.
git push <remote> --tags Transfiere todas las tags al repositorio remoto.

git rebase
Se trata de un comando que permite volver a reescribir la historia de commits, desplazando una determinada rama hasta el final de otra rama determinada (reasignación de una nueva base).
git rebase <ramaDestino> Siendo la rama actual la rama que se desea mover (checked out), se indicará la rama destino (p.e. master).
git rebase <ramaDestino> <ramaOrigen> Se realiza un checkout de la rama origen, y se implementa un rebase sobre la rama destino.
NOTA: No se debe reescribir la historia de commits que ya haya sido compartida con otras personas. Es decir, si solamente se ha trabajado localmente (o en una forked repository) y si conocemos que nadie ha utilizado nuestra rama.
La reescritura de la historia de commits debe realizarse con mucha precaución. En un rebase de tipo normal, lo que sucede es que se mueven un conjunto de commits hasta un nuevo ancestro (nueva base). En el ejemplo siguiente, los commits B y C son reubicados en el commits D al final de la rama. Como la cadena de ancestros es diferentes, se generan nuevos commits B' y C':

En la situación inicial de la izquierda, se observa que es un caso típico donde se realizará un merge commit, sin embargo, tras realizar un rebase ya no será necesario un merge commit sino que se implementará simplemente un fast-forward merge.
En el proceso de rebase, al igual que en un merge, pueden producirse conflictos que hayan de solucionarse.
Ventajas de un rebase:
- Es posible incorporar nuevas caracteristicas desde la rama padre.
- Convierte el merge en uno de tipo fast-forward.
- Se evitan commits innecesarios consiguiendo una historia del proyecto más limpia.
Desventajas de un rebase:
- Es posible que surjan conflictos de ficheros en el proceso que haya que resolver.
- Si se ha compartido el proyecto es posible que surjan problemas, ya que los identificadores de commits cambian.
- Se está cambiando la historia de commits reescribiéndola nuevamente.
Cuando se produce un conflicto al realizar un merge, git status sugiere dos opciones principales, modificar los ficheros involucrados en el conflicto y ejecutar git rebase --continue para finalizarlo, o ejecutar git rebase --abort para cancelarlo y volver a la situación previa anterior al rebase.
Reescribir la historia de commits
Una vez que se ha escrito una historia de commits que representa la evolución del proyecto, es posible realizar ajustes y modificaciones y si se determina que dicha historia quedaría mejor descrita tras llevar a cabo algunos cambios.
Dos maneras de llevar a cabo modificaciones son las siguientes:
- Amending commit: Es posible modificar el último commit, cambiando en mensaje asociado o los ficheros incluidos. Esto crea un nuevo ID del commit (nuevo SHA1-Reescribiendo la historia). Para modificar el mensaje descriptivo asociado al último commit, ejecutamos git commit --amend -m "nueva descripción". Para modificar uno o varios ficheros incluidos en el último commit, deberemos realizar las modificaciones en el fichero/s que deseemos, incluirlos en el índice (staging area) y ejecutar git commit --amend --no-edit (--no-edit indica que se debe mantener el mensaje descriptivo del commit).
- Interactive rebase: Permite realizar operaciones de cambio de mensajes en los commits, cambiar el orden de varios commits, modificar los ficheros de un commit, unir varios commits en uno solo, dividir un commit en varios o eliminar commits completamente. Para ello utilizaremos el comando git rebase -i <IDcommit> donde indicaremos el SHA-1 del commit a partir del cual queremos reescribir la historia.
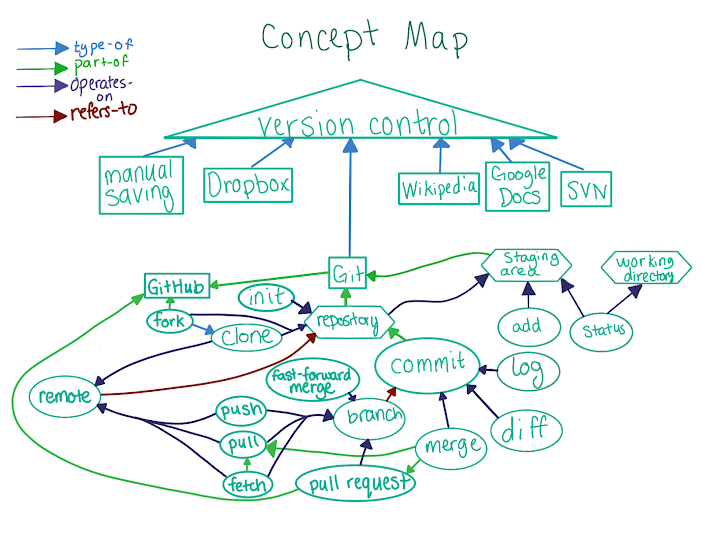 |
| Relación entre diferentes conceptos en Git |
Pull Request
Un pull request es una característica particular de las plataformas web que implementan Git, como Github o Bitbucket.
El objetivo final de un pull request es realizar una integración (merge) de una rama que incluye una serie de modificaciones, en el proyecto para el que han sido desarrolladas. Un pull request posibilita la comunicación entre los miembros del equipo mediante notificaciones, comentarios y revisiones de código, dado lugar a un foro de discusión donde se determinará si finalmente la rama candidata se incluye en el proyecto o no.
Dado que para llevar a cabo pull request es necesario llevarlo a cabo mediante repositorios remotos, existen dos configuraciones posibles:
- Repositorio remoto único: Disponemos de acceso de escritura, y el pull request consistirá en realizar un merge de una nueva rama en la rama master del repositorio remoto.
- Repositorio remoto doble: Es el típico caso de contribución sobre un repositorio en el que no tenemos acceso de escritura. Para ello, se realiza una copia (fork) del repositorio base (upstream), donde se lleva a cabo el trabajo. El pull request consistirá en solicitar una integración de la nueva rama desde el repositorio de trabajo remoto copia, al repositorio base original donde no se dispone de acceso de escritura.
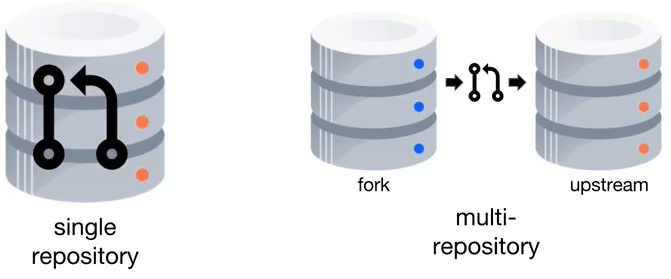
Un pull request es posible abrirlo o crearlo en cualquier momento posterior a la creación de la rama de trabajo. Los motivos que llevan a crear un pull request pueden ser:
- Abrir una consulta con el equipo de trabajo solicitando comentarios sobre la rama de trabajo.
- El trabajo está listo para ser incorporado sobre la rama principal (master).
La creación de un pull request en un repositorio único se realiza de la siguiente manera:
- git checkout -b nombreRamaTrabajo para crear un nueva rama donde realizar el trabajo.
- Crear un conjunto de commits, donde se recogen el trabajo.
- git push --set-upstream origin nombreRamaTrabajo (set-upstream configura que la rama sea tracking.
- En Github o Bitbucket, crearemos un pull request habilitando un espacio de discusión sobre el trabajo realizado en la rama de trabajo. Finalmente decidiremos si realizar el merge o no.
- git push -d <remote> nombreRamaTrabajo (elimina del remoto la rama de trabajo al finalizar)
Repositorio Fork
Se trata de un repositorio copia del repositorio original ("source of truth" o upstream), duplicado en la cuenta online de la plataforma hosting Git (Github o Bitbucket).
Un repositorio fork sirve para realizar pruebas, experimentos y aprendizajes en base a un repositorio oficial de manera separada. También puede utilizarse para crear ramas nuevas y solicitar, mediante pull requests que sean insertadas en el repositorio origen (upstream). Esta es la manera de contribuir en un repositorio en el que no tenemos permisos de escritura.
Un fork puede ser tambien el origen de una nueva rama del proyecto alcanzando entidad propia, es decir, convertirse en una nueva línea de desarrollo.
Se trata de un repositorio copia del repositorio original ("source of truth" o upstream), duplicado en la cuenta online de la plataforma hosting Git (Github o Bitbucket).
Un repositorio fork sirve para realizar pruebas, experimentos y aprendizajes en base a un repositorio oficial de manera separada. También puede utilizarse para crear ramas nuevas y solicitar, mediante pull requests que sean insertadas en el repositorio origen (upstream). Esta es la manera de contribuir en un repositorio en el que no tenemos permisos de escritura.
Un fork puede ser tambien el origen de una nueva rama del proyecto alcanzando entidad propia, es decir, convertirse en una nueva línea de desarrollo.
Los flujos de trabajo en Git permiten adaptar el desarrollo del trabajo a la propia idiosincrasia del equipo, dado que son altamente flexibles y ajustables.
Los principales flujos de trabajo son:
- Workflow centralizado: Es la expresión más simple de flujo. Se dispone de un repositorio remoto que contiene una sola rama con el trabajo final. Los diferentes miembros del equipo trabajan de manera autónoma localmente en su propia rama master. No se utilizan pull request para debatir o discutir la inclusión de nuevo trabajo al repositorio principal remoto.
- Workflow basado en 'Topic branches': El trabajo se lleva a cabo mediante ramas topic, las cuales recogen el desarrollo de una característica concreta de producto/servicio. Existe un sólo repositorio remoto, y se utilizan los pull request para decidir la inclusión del trabajo realizado (topic branches) por los diferentes componentes del equipo. Los pulls request aceptados son insertados en la rama principal del repositorio remoto.
- Forking workflow: Esta tipología de trabajo, a diferencia de las anteriores, implica el uso de múltiples repositorios remotos. Uno de estos repositorios remotos contiene el trabajo final o definitivo y se le conoce como upstream (source of truth). Cada miembro del equipo trabaja con un repositorio remoto duplicado (forked) del repositorio principal, y el trabajo realizado se envía a dicho repositorio mediante pull requests. De esta forma, los miembros del equipo no necesitan tener acceso de escritura al repositorio principal (upstream), con lo que este sistema es utilizado en múltiples proyectos Open Source. Trabajar con repositorios remotos duplicados (forked remote repositories) tiene la ventaja de que puedes trabajar en ramas topic sin compartir el trabajo, constituyendo además una manera de tener el trabajo salvaguardado. Este modo de trabajo tiene el inconveniente que el repositorio remoto upstream y el repositorio remoto forked se desincronizan fácilmente, siendo responsabilidad el repositorio forked el mantenerse actualizado.
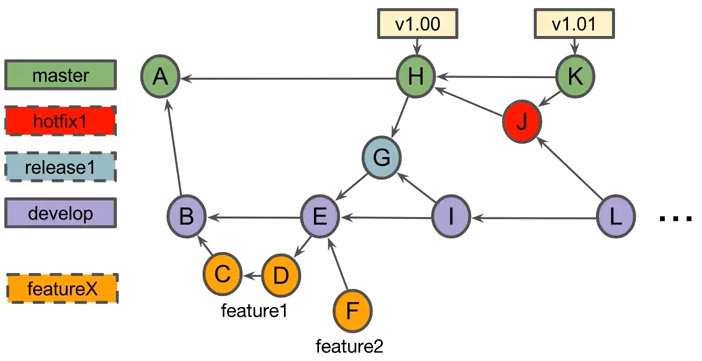
- Gitflow workflow: Este flujo de trabajo permite liberar diferentes versiones del desarrollo del producto de manera segura. Permite continuar el desarrollo del proyecto mientras al mismo tiempo se llevan a cabo lanzamientos de versiones y solucionado de problemas. Esta tipología de trabajo implica la utilización de diferentes tipos de ramas, de larga y de corta duración. En la ilustración inferior vemos un ejemplo de desarrollo de proyecto software, en el que las ramas master y develop forman las ramas de larga duración y el resto las de corta duración. En la rama master (salvo el commit inicial de comienzo de proyecto - Fichero README.md) lo constituyen versiones del software que los clientes pueden utilizar. A partir del commit inicial en la rama master, se crea la rama develop, que contendrá todas las características que se irán construyendo mediante las ramas topic (feature branches), las cuales son de corta duración y representan nuevas características que se añaden al software. En estas ramas es donde se realiza verdaderamente el trabajo de desarrollo, de manera que cuando el trabajo está terminado, se realiza la integración en la rama develop (merge) posiblemente mediante pull requests. En este ejemplo, se muestra la rama realease1, la cual represente la próxima liberalización de una nueva versión del software. Sobre esta rama realease se llevarán a cabo las pertinentes baterías de test para finalmente proceder a la publicación. En el ejemplo, el commit G representa un bug corregido sobre la versión release del software, a partir del cual se realiza la publicación final sobre la rama master (v1.00). Es interesante remarcar, que sobre la rama master solamente aparecen commits de tipo merge, cuando el equipo determina que las respectivas versiones release están maduras. De igual modo, la rama develop la integran commits de tipo merge procedentes de las ramas topic y de los commit donde se llevaron a cabo correcciones de errores (p.e. en ramas release y hotfix), de esta manera, bug corregidos no vuelven a aparecer en futuras versiones. Para el caso de solucionado de errores sobre versiones ya liberadas, se utilizan las rama tipo hotfix, donde se lleva a cabo el trabajo de solucionado del error. Las ramas hotfix se llevan a cabo desde la rama master y no desde develop, ya que si no, se incorporarían nuevas características desarrolladas, las cuales están reservadas para la siguiente versión release. El trabajo realizado en las ramas hotfix debe ser lo mínimo imprescindible para limitar riesgos. Del mismo modo que en las ramas release, en las ramas hotfix es necesario hacer un merge de los errores solucionados sobre la rama develop, para evitar que dichos errores aparezcan el versiones release posteriores. Una de las reglas que muchos equipos de trabajo utilizan es que la rama master solo debe contener commits de tipo merge procedentes de ramas release o hotfix y nunca de la rama develop. Así mismo, otra de las reglas es que si se realiza un commit sobre la rama master, al mismo tiempo se debe realizar un commit sobre la rama develop para incluir el trabajo realizado en futuras versiones release.
Una manera de trabajar de forma colaborativa en Github a través de pull request sería la siguiente:
- Hacer un fork del repositorio oficial a la cuenta de Github.
- Clonar en el PC de trabajo (local) el repositorio fork.
- Se crea automáticamente un remote 'origin' apuntando al repositorio fork. Crear un remote más llamado 'upstream' que apunta al repositorio oficial o base para poder descargar las actualizaciones del resto de colaboradores (y poder actualizar nuestro fork haciendo push después)
- Para trabajar en las nuevas características, crearemos una nueva rama donde los insertaremos (topic branch).
- Hacer push de la rama creada con los cambios al repositorio fork una vez finalizados.
- En Github, crear un pull request de la rama creada al repositorio oficial o base (upstream).
- El administrador de repositorio base, admitirá o comenzará una discusión para aceptar los cambios enviados.
- Si hay conflicto con los cambios enviados (alguien del equipo modifica las mismas líneas de los ficheros) será necesario bajarse la última versión del repositorio oficial en local (pull rama master), y luego en local hacer una merge de la rama master en la rama creada con los cambios.
- Solucionar los conflictos existentes.
- Volveremos a subir (push) la rama con los cambios al repositorio fork, lo cual, actualizará el pull request de manera automática (Github también realiza la gestión de notificaciones a los colaboradores para saber cuando se producen novedades y cambios en el repositorio)
- Finalmente el administrador del repositorio oficial acepta los cambios y pasan a formar parte de la rama master oficial.
Aquí concluye el resumen de los conceptos más básicos relacionados con el sistema gestor de control de versiones Git y Github. Para realizarlo se han utilizado las siguientes fuentes de información:
No hay comentarios:
Publicar un comentario
Por favor, si consideras necesario realizar algún aporte, feel free to do it!!